Step: 1
Download the tarball from cloudera Site or simple click here .
Step: 2
Untar the tarball on anyplace or you ca do in home directory as I did
$ tar –xvzf hadoop-2.0.0-cdh4.1.2.tar.gz
Step: 3
Set the different home directory in /etc/profile
export JAVA_HOME=/usr/java/jdk1.6.0_22
export PATH=/usr/java/jdk1.6.0_22/bin:"$PATH"
export HADOOP_HOME=/home/hadoop/hadoop-2.0.0-cdh4.1.2
Step: 4
Create hadoop directory in /etc , Create a softlink in /etc/hadoop/conf - > $HADOOP_HOME/etc/hadoop
$ ln –s /home/hadoop/hadoop-2.0.0-cdh4.1.2/etc/hadoop /etc/hadoop/conf
Step : 5
Create different directories listed here
For datanode
$ mkdir ~/dfs/dn1 ~/dfs/dn2
$ mkdir /var/log/hadoop
For Namenode
$ mkdir ~/dfs/nn ~/dfs/nn1
For SecondaryNamenode
$ mkdir ~/dfs/snn
for Nodemanager
$ mkdir ~/yarn/local-dir1 ~/yarn/local-dir2
$ mkdir ~/yarn/apps
for Mapred
$ mkdir ~/yarn/tasks1 ~/yarn/tasks2
Step: 6
After Creating all the Directories now its time for setting up Hadoop Conf File, Add following properties in there xml files.
1:- Core-Site.xml
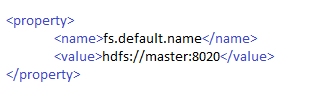

3:- Hdfs-site.xml

4: Yarn-Site.xml


Step: 7
After completion of xmls edits, now we need to bit modify the hadoop-en.sh and yarn-env.sh ,
Hadoop-env.sh
Replace this line
export HADOOP_CLIENT_OPTS="-Xmx128m $HADOOP_CLIENT_OPTS"
with
export HADOOP_CLIENT_OPTS="-Xmx1g $HADOOP_CLIENT_OPTS"
motive is to increase the memory requirement of hadop clients , to run the jobs.
Yarn-env.sh
If you are running jobs with different user then yarn , change here
export HADOOP_YARN_USER=${HADOOP_YARN_USER:-hadoop}
Step : 8
Now you completed the hadoop installation , this is the time to format and run the daemons process.
Format hadoop filesystem
$ $HADOOP_HOME/bin/hdfs namenode –format
Once all the necessary configuration is complete, distribute the files to theHADOOP_CONF_DIR directory on all the machines.
export HADOOP_CONF_DIR=/etc/hadoop/conf
$ $HADOOP_HOME/bin/hadoop fs –mkdir /user
Step : 9
Hadoop Startup
Start the HDFS with the following command, run on the designated
NameNode:
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs $1 secondarynamenode
Run a script to start DataNodes on all slaves:
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start datanode
Start the YARN with the following command, run on the designated
ResourceManager:
$ $HADOOP_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start resourcemanager
Run a script to start NodeManagers on all slaves:
$ $HADOOP_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start nodemanager
Start the MapReduce JobHistory Server with the following command, run on the designated server:
$ $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver --config $HADOOP_CONF_DIR
Hadoop Shutdown
Stop the NameNode with the following command, run on the designated NameNode:
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs stop namenode
Run a script to stop DataNodes on all slaves:
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs stop datanode
Stop the ResourceManager with the following command, run on the designated ResourceManager:
$ $HADOOP_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop resourcemanager
Run a script to stop NodeManagers on all slaves:
$ $HADOOP_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop nodemanager
Stop the WebAppProxy server. If multiple servers are used with load balancing it should be run on each of them:
$ $HADOOP_HOME/bin/yarn stop proxyserver --config $HADOOP_CONF_DIR
Stop the MapReduce JobHistory Server with the following command, run on the designated server:
$ $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh stop historyserver --config $HADOOP_CONF_DIR
Now After starting successfully you can Check the namenode Url at
http://master:50070/dfsnodelist.jsp?whatNodes=LIVE
Yarn URl at
http://master:8088/cluster/nodes
Step: 10
Running any Example to check if its working or not
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.0.0-cdh4.1.2.jar pi 5 100
Run the Pi example to verify that and you can see it on yarn url, if its working or not.
Some Tweaks:
You can set alias in .profile
alias hd=”$HADOOP_HOME/bin/hadoop ”
or create small shell script to start and stop those process like
$ vi dfs.sh
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs $1 namenode
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs $1 datanode
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs $1 secondarynamenode
after adding these lines you can start the process just by running dfs.sh
$ sh dfs.sh start/stop
Download the tarball from cloudera Site or simple click here .
Step: 2
Untar the tarball on anyplace or you ca do in home directory as I did
$ tar –xvzf hadoop-2.0.0-cdh4.1.2.tar.gz
Step: 3
Set the different home directory in /etc/profile
export JAVA_HOME=/usr/java/jdk1.6.0_22
export PATH=/usr/java/jdk1.6.0_22/bin:"$PATH"
export HADOOP_HOME=/home/hadoop/hadoop-2.0.0-cdh4.1.2
Step: 4
Create hadoop directory in /etc , Create a softlink in /etc/hadoop/conf - > $HADOOP_HOME/etc/hadoop
$ ln –s /home/hadoop/hadoop-2.0.0-cdh4.1.2/etc/hadoop /etc/hadoop/conf
Step : 5
Create different directories listed here
For datanode
$ mkdir ~/dfs/dn1 ~/dfs/dn2
$ mkdir /var/log/hadoop
For Namenode
$ mkdir ~/dfs/nn ~/dfs/nn1
For SecondaryNamenode
$ mkdir ~/dfs/snn
for Nodemanager
$ mkdir ~/yarn/local-dir1 ~/yarn/local-dir2
$ mkdir ~/yarn/apps
for Mapred
$ mkdir ~/yarn/tasks1 ~/yarn/tasks2
Step: 6
After Creating all the Directories now its time for setting up Hadoop Conf File, Add following properties in there xml files.
1:- Core-Site.xml
2:- mapred-site.xml
3:- Hdfs-site.xml
4: Yarn-Site.xml
Step: 7
After completion of xmls edits, now we need to bit modify the hadoop-en.sh and yarn-env.sh ,
Hadoop-env.sh
Replace this line
export HADOOP_CLIENT_OPTS="-Xmx128m $HADOOP_CLIENT_OPTS"
with
export HADOOP_CLIENT_OPTS="-Xmx1g $HADOOP_CLIENT_OPTS"
motive is to increase the memory requirement of hadop clients , to run the jobs.
Yarn-env.sh
If you are running jobs with different user then yarn , change here
export HADOOP_YARN_USER=${HADOOP_YARN_USER:-hadoop}
Step : 8
Now you completed the hadoop installation , this is the time to format and run the daemons process.
Format hadoop filesystem
$ $HADOOP_HOME/bin/hdfs namenode –format
Once all the necessary configuration is complete, distribute the files to theHADOOP_CONF_DIR directory on all the machines.
export HADOOP_CONF_DIR=/etc/hadoop/conf
$ $HADOOP_HOME/bin/hadoop fs –mkdir /user
Step : 9
Hadoop Startup
Start the HDFS with the following command, run on the designated
NameNode:
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs $1 secondarynamenode
Run a script to start DataNodes on all slaves:
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start datanode
Start the YARN with the following command, run on the designated
ResourceManager:
$ $HADOOP_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start resourcemanager
Run a script to start NodeManagers on all slaves:
$ $HADOOP_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start nodemanager
Start the MapReduce JobHistory Server with the following command, run on the designated server:
$ $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver --config $HADOOP_CONF_DIR
Hadoop Shutdown
Stop the NameNode with the following command, run on the designated NameNode:
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs stop namenode
Run a script to stop DataNodes on all slaves:
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs stop datanode
Stop the ResourceManager with the following command, run on the designated ResourceManager:
$ $HADOOP_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop resourcemanager
Run a script to stop NodeManagers on all slaves:
$ $HADOOP_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop nodemanager
Stop the WebAppProxy server. If multiple servers are used with load balancing it should be run on each of them:
$ $HADOOP_HOME/bin/yarn stop proxyserver --config $HADOOP_CONF_DIR
Stop the MapReduce JobHistory Server with the following command, run on the designated server:
$ $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh stop historyserver --config $HADOOP_CONF_DIR
Now After starting successfully you can Check the namenode Url at
http://master:50070/dfsnodelist.jsp?whatNodes=LIVE
Yarn URl at
http://master:8088/cluster/nodes
Step: 10
Running any Example to check if its working or not
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.0.0-cdh4.1.2.jar pi 5 100
Run the Pi example to verify that and you can see it on yarn url, if its working or not.
Some Tweaks:
You can set alias in .profile
alias hd=”$HADOOP_HOME/bin/hadoop ”
or create small shell script to start and stop those process like
$ vi dfs.sh
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs $1 namenode
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs $1 datanode
$ $HADOOP_HOME/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs $1 secondarynamenode
after adding these lines you can start the process just by running dfs.sh
$ sh dfs.sh start/stop
No comments:
Post a Comment