Introduction
HDFS, the Hadoop Distributed File System, is a distributed file system designed to hold very large amounts of data (terabytes or even petabytes), and provide high-throughput access to this information. Files are stored in a redundant fashion across multiple machines to ensure their durability to failure and high availability to very parallel applications. This module introduces the design of this distributed file system and instructions on how to operate it.
A distributed file system is designed to hold a large amount of data and provide access to this data to many clients distributed across a network.
How to solve the Traditional System problems by using Big Data
Traditional System Problem : Data is too big store in one computer
Today's big data is 'too big' to store in ONE single computer -- no matter how powerful it is and how much storage it has. This eliminates lot of storage system and databases that were built for single machines. So we are going to build the system to run on multiple networked computers. The file system will look like a unified single file system to the 'outside' world
Hadoop solution : Data is stored on multiple computers

Traditional System Problem : Very high end machines are expensive
Now that we have decided that we need a cluster of computers, what kind of machines are they? Traditional storage machines are expensive with top-end components, sometimes with 'exotic' components (e.g. fiber channel for disk arrays, etc). Obviously these computers cost a pretty penny.
We want our system to be cost-effective, so we are not going to use these 'expensive' machines. Instead we will opt to use commodity hardware. By that we don't mean cheapo desktop class machines. We will use performant server class machines -- but these will be commodity servers that you can order from any of the vendors (Dell, HP, etc)
Hadoop solution : Run on commodity hardware

Traditional System Problem : Commodity hardware will fail
In the old days of distributed computing, failure was an exception, and hardware errors were not tolerated well. So companies providing gear for distributed computing made sure their hardware seldom failed. This is achieved by using high quality components, and having backup systems (in come cases backup to backup systems!). So the machines are engineered to withstand component failures, but still keep functioning. This line of thinking created hardware that is impressive, but EXPENSIVE!
On the other hand we are going with commodity hardware. These don't have high end whiz bang components like the main frames mentioned above. So they are going to fail -- and fail often. We need to prepared for this. How?
The approach we will take is we build the 'intelligence' into the software. So the cluster software will be smart enough to handle hardware failure. The software detects hardware failures and takes corrective actions automatically -- without human intervention. Our software will be smarter!
Hadoop solution : Software is intelligent enough to deal with hardware failure
Traditional System Problem : hardware failure may lead to data loss
So now we have a network of machines serving as a storage layer. Data is spread out all over the nodes. What happens when a node fails (and remember, we EXPECT nodes to fail). All the data on that node will become unavailable (or lost). So how do we prevent it?
One approach is to make multiple copies of this data and store them on different machines. So even if one node goes down, other nodes will have the data. This is called 'replication'. The standard replication is 3 copies.
Hadoop Solution : replicate (duplicate) data

Traditional System Problem : how will the distributed nodes co-ordinate among themselves
Since each machine is part of the 'storage', we will have a 'daemon' running on each machine to manage storage for that machine. These daemons will talk to each other to exchange data.
OK, now we have all these nodes storing data, how do we coordinate among them? One approach is to have a MASTER to be the coordinator. While building distributed systems with a centralized coordinator may seem like an odd idea, it is not a bad choice. It simplifies architecture, design and implementation of the system
So now our architecture looks like this. We have a single master node and multiple worker nodes.
Hadoop solution : There is a master node that co-ordinates all the worker nodes

Overview of HDFS
HDFS has many similarities with other distributed file systems, but is different in several respects. One noticeable difference is HDFS's write-once-read-many model that relaxes concurrency control requirements, simplifies data coherency, and enables high-throughput access.
Another unique attribute of HDFS is the viewpoint that it is usually better to locate processing logic near the data rather than moving the data to the application space.
HDFS rigorously restricts data writing to one writer at a time. Bytes are always appended to the end of a stream, and byte streams are guaranteed to be stored in the order written.
HDFS has many goals. Here are some of the most notable:

Master / worker design
In an HDFS cluster, there is ONE master node and many worker nodes. The master node is called the Name Node (NN) and the workers are called Data Nodes (DN). Data nodes actually store the data. They are the workhorses.
Name Node is in charge of file system operations (like creating files, user permissions, etc.). Without it, the cluster will be inoperable. No one can write data or read data.
This is called a Single Point of Failure. We will look more into this later.
Runs on commodity hardware
As we saw hadoop doesn't need fancy, high end hardware. It is designed to run on commodity hardware. The Hadoop stack is built to deal with hardware failure and the file system will continue to function even if nodes fail.
HDFS is resilient (even in case of node failure)
The file system will continue to function even if a node fails. Hadoop accomplishes this by duplicating data across nodes.
Data is replicated
So how does Hadoop keep data safe and resilient in case of node failure? Simple, it keeps multiple copies of data around the cluster.
To understand how replication works, lets look at the following scenario. Data segment #2 is replicated 3 times, on data nodes A, B and D. Lets say data node A fails. The data is still accessible from nodes B and D.
HDFS is better suited for large files
Generic file systems, say like Linux EXT file systems, will store files of varying size, from a few bytes to few gigabytes. HDFS, however, is designed to store large files. Large as in a few hundred megabytes to a few gigabytes.
Why is this?
HDFS was built to work with mechanical disk drives, whose capacity has gone up in recent years. However, seek times haven't improved all that much. So Hadoop tries to minimize disk seeks.
Files are write-once only (not updateable)
HDFS supports writing files once (they cannot be updated). This is a stark difference between HDFS and a generic file system (like a Linux file system). Generic file systems allows files to be modified.
However appending to a file is supported. Appending is supported to enable applications like HBase.
Namenode
Namenode acts as master in HDFS. It stores file system metadata and transaction log of changes happening in file system. Namenode does not store actual file data.
Namenode also maintains block map report sent by individual data nodes. Whenever any client wants to perform any operation on file. It contacts Namenode, which responds to this request by providing block map and Datanode information.
Datanode
Datanode is the actual storage component in HDFS. Datanode store data in HDFS file system. A typical production HDFS cluster has one Namenode and multiple Datanodes.
Datanodes talks to Namenode in the form of heartbeats to let Namenode know that particular Datanode is alive and Block report which consists of list of data block held by that particular Datanode. Datanodes also talks to other Datanode directly for data replication.
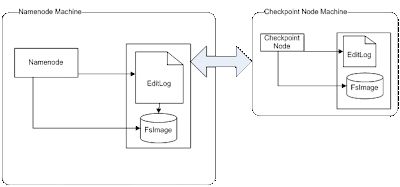
Checkpoint Node
HDFS stores its namespace and file system transaction log in FsImage and EditLog files on Namenode local disk. When Namenode starts-up, changes recorded in EditLog are merged with FsImage, So that HDFS always have up-to date file system metadata. After merging the changes from EditLog to FsImage, HDFS removes the old FsImage copy and replaces it with newer one as it has new updated FsImage which represents current state of HDFS and then it opens up new EditLog.
In any HDFS instance, Namenode is the single point of failure because if Namenode maintains the namespace and Editlog, if these files are corrupted or lost, whole cluster will go down. To avoid this, multiple copies of FsImage and EditLog can be maintained on different machine using checkpoint node.
Checkpoint node creates the periodic checkpoints of namespace and edit log. Checkpoint node downloads the latest copies of FsImage and EditLog from active Namenode, stores them locally, merges them and uploads back to active Namenode.
A true production Hadoop cluster should have checkpoint node running on different machine which is of same configuration like active namenode in terms of memory.
The Checkpoint node stores the latest checkpoint in a directory which has same structure as the NameNode’s directory. This allows the checkpointed image to be always available for reading by the NameNode if necessary. It is possible to have multiple checkpoint node in a cluster. This can be specified in HDFS configuration file.
Backup Node
Backup node works the same way like checkpoint. Backup node provides checkpoint functionality and in addition to this it also maintains updated copies of file system namespace in its memory. This in-memory copy is in synchronized with Namenode. Backup node applies the EditLog changes to in-memory copy namespace and stores it on disk. This way backup node always have up to date copies of EditLog and FsImage on disk and in memory.
In contrast with checkpoint node, where checkpoint node needs to download the copies of FsImage and EditLog, Backup node does not need to download these copies, as it always have updated copy of namespace in its memory. It only needs to apply latest EditLog changes to in-memory namespace and stores the copies of FsImage and Edit log on its local disk. Due to this backup node checkpoint process is more efficient than checkpoint node.
Backup node memory requirement is same as Namenode as it needs to maintain namespace in memory like Namenode. You can have only one backup node (multiple backup node are not supported at this point of time) and no checkpoint node can run, when backup node is running. Means you can have either backup node or checkpoint node, not both at a time.
Since backup node can maintain the copies of namespace in memory, you can start Namenode in a such a way that Namenode no longer needs to maintain namespace in its own memory, Namenode node can delegate this tack to backup node. In such case Namenode will import the namespace from backup node memory whenever it requires namespace. This can be done by starting Namenode with –importCheckpoint option.
HDFS, the Hadoop Distributed File System, is a distributed file system designed to hold very large amounts of data (terabytes or even petabytes), and provide high-throughput access to this information. Files are stored in a redundant fashion across multiple machines to ensure their durability to failure and high availability to very parallel applications. This module introduces the design of this distributed file system and instructions on how to operate it.
A distributed file system is designed to hold a large amount of data and provide access to this data to many clients distributed across a network.
How to solve the Traditional System problems by using Big Data
Traditional System Problem : Data is too big store in one computer
Today's big data is 'too big' to store in ONE single computer -- no matter how powerful it is and how much storage it has. This eliminates lot of storage system and databases that were built for single machines. So we are going to build the system to run on multiple networked computers. The file system will look like a unified single file system to the 'outside' world
Hadoop solution : Data is stored on multiple computers

Traditional System Problem : Very high end machines are expensive
Now that we have decided that we need a cluster of computers, what kind of machines are they? Traditional storage machines are expensive with top-end components, sometimes with 'exotic' components (e.g. fiber channel for disk arrays, etc). Obviously these computers cost a pretty penny.
We want our system to be cost-effective, so we are not going to use these 'expensive' machines. Instead we will opt to use commodity hardware. By that we don't mean cheapo desktop class machines. We will use performant server class machines -- but these will be commodity servers that you can order from any of the vendors (Dell, HP, etc)
Hadoop solution : Run on commodity hardware

Traditional System Problem : Commodity hardware will fail
In the old days of distributed computing, failure was an exception, and hardware errors were not tolerated well. So companies providing gear for distributed computing made sure their hardware seldom failed. This is achieved by using high quality components, and having backup systems (in come cases backup to backup systems!). So the machines are engineered to withstand component failures, but still keep functioning. This line of thinking created hardware that is impressive, but EXPENSIVE!
On the other hand we are going with commodity hardware. These don't have high end whiz bang components like the main frames mentioned above. So they are going to fail -- and fail often. We need to prepared for this. How?
The approach we will take is we build the 'intelligence' into the software. So the cluster software will be smart enough to handle hardware failure. The software detects hardware failures and takes corrective actions automatically -- without human intervention. Our software will be smarter!
Hadoop solution : Software is intelligent enough to deal with hardware failure
Traditional System Problem : hardware failure may lead to data loss
So now we have a network of machines serving as a storage layer. Data is spread out all over the nodes. What happens when a node fails (and remember, we EXPECT nodes to fail). All the data on that node will become unavailable (or lost). So how do we prevent it?
One approach is to make multiple copies of this data and store them on different machines. So even if one node goes down, other nodes will have the data. This is called 'replication'. The standard replication is 3 copies.
Hadoop Solution : replicate (duplicate) data

Traditional System Problem : how will the distributed nodes co-ordinate among themselves
Since each machine is part of the 'storage', we will have a 'daemon' running on each machine to manage storage for that machine. These daemons will talk to each other to exchange data.
OK, now we have all these nodes storing data, how do we coordinate among them? One approach is to have a MASTER to be the coordinator. While building distributed systems with a centralized coordinator may seem like an odd idea, it is not a bad choice. It simplifies architecture, design and implementation of the system
So now our architecture looks like this. We have a single master node and multiple worker nodes.
Hadoop solution : There is a master node that co-ordinates all the worker nodes

Overview of HDFS
HDFS has many similarities with other distributed file systems, but is different in several respects. One noticeable difference is HDFS's write-once-read-many model that relaxes concurrency control requirements, simplifies data coherency, and enables high-throughput access.
Another unique attribute of HDFS is the viewpoint that it is usually better to locate processing logic near the data rather than moving the data to the application space.
HDFS rigorously restricts data writing to one writer at a time. Bytes are always appended to the end of a stream, and byte streams are guaranteed to be stored in the order written.
HDFS has many goals. Here are some of the most notable:
- Fault tolerance by detecting faults and applying quick, automatic recovery
- Data access via MapReduce streaming
- Simple and robust coherency model
- Processing logic close to the data, rather than the data close to the processing logic
- Portability across heterogeneous commodity hardware and operating systems
- Scalability to reliably store and process large amounts of data
- Economy by distributing data and processing across clusters of commodity personal computers
- Efficiency by distributing data and logic to process it in parallel on nodes where data is located
- Reliability by automatically maintaining multiple copies of data and automatically redeploying processing logic in the event of failures
{kind=link}

Master / worker design
In an HDFS cluster, there is ONE master node and many worker nodes. The master node is called the Name Node (NN) and the workers are called Data Nodes (DN). Data nodes actually store the data. They are the workhorses.
Name Node is in charge of file system operations (like creating files, user permissions, etc.). Without it, the cluster will be inoperable. No one can write data or read data.
This is called a Single Point of Failure. We will look more into this later.
Runs on commodity hardware
As we saw hadoop doesn't need fancy, high end hardware. It is designed to run on commodity hardware. The Hadoop stack is built to deal with hardware failure and the file system will continue to function even if nodes fail.
HDFS is resilient (even in case of node failure)
The file system will continue to function even if a node fails. Hadoop accomplishes this by duplicating data across nodes.
Data is replicated
So how does Hadoop keep data safe and resilient in case of node failure? Simple, it keeps multiple copies of data around the cluster.
To understand how replication works, lets look at the following scenario. Data segment #2 is replicated 3 times, on data nodes A, B and D. Lets say data node A fails. The data is still accessible from nodes B and D.
HDFS is better suited for large files
Generic file systems, say like Linux EXT file systems, will store files of varying size, from a few bytes to few gigabytes. HDFS, however, is designed to store large files. Large as in a few hundred megabytes to a few gigabytes.
Why is this?
HDFS was built to work with mechanical disk drives, whose capacity has gone up in recent years. However, seek times haven't improved all that much. So Hadoop tries to minimize disk seeks.
Files are write-once only (not updateable)
HDFS supports writing files once (they cannot be updated). This is a stark difference between HDFS and a generic file system (like a Linux file system). Generic file systems allows files to be modified.
However appending to a file is supported. Appending is supported to enable applications like HBase.
Namenode
Namenode acts as master in HDFS. It stores file system metadata and transaction log of changes happening in file system. Namenode does not store actual file data.
Namenode also maintains block map report sent by individual data nodes. Whenever any client wants to perform any operation on file. It contacts Namenode, which responds to this request by providing block map and Datanode information.
Datanode
Datanode is the actual storage component in HDFS. Datanode store data in HDFS file system. A typical production HDFS cluster has one Namenode and multiple Datanodes.
Datanodes talks to Namenode in the form of heartbeats to let Namenode know that particular Datanode is alive and Block report which consists of list of data block held by that particular Datanode. Datanodes also talks to other Datanode directly for data replication.
Checkpoint Node
HDFS stores its namespace and file system transaction log in FsImage and EditLog files on Namenode local disk. When Namenode starts-up, changes recorded in EditLog are merged with FsImage, So that HDFS always have up-to date file system metadata. After merging the changes from EditLog to FsImage, HDFS removes the old FsImage copy and replaces it with newer one as it has new updated FsImage which represents current state of HDFS and then it opens up new EditLog.
In any HDFS instance, Namenode is the single point of failure because if Namenode maintains the namespace and Editlog, if these files are corrupted or lost, whole cluster will go down. To avoid this, multiple copies of FsImage and EditLog can be maintained on different machine using checkpoint node.
Checkpoint node creates the periodic checkpoints of namespace and edit log. Checkpoint node downloads the latest copies of FsImage and EditLog from active Namenode, stores them locally, merges them and uploads back to active Namenode.
A true production Hadoop cluster should have checkpoint node running on different machine which is of same configuration like active namenode in terms of memory.
The Checkpoint node stores the latest checkpoint in a directory which has same structure as the NameNode’s directory. This allows the checkpointed image to be always available for reading by the NameNode if necessary. It is possible to have multiple checkpoint node in a cluster. This can be specified in HDFS configuration file.

Backup Node
Backup node works the same way like checkpoint. Backup node provides checkpoint functionality and in addition to this it also maintains updated copies of file system namespace in its memory. This in-memory copy is in synchronized with Namenode. Backup node applies the EditLog changes to in-memory copy namespace and stores it on disk. This way backup node always have up to date copies of EditLog and FsImage on disk and in memory.
In contrast with checkpoint node, where checkpoint node needs to download the copies of FsImage and EditLog, Backup node does not need to download these copies, as it always have updated copy of namespace in its memory. It only needs to apply latest EditLog changes to in-memory namespace and stores the copies of FsImage and Edit log on its local disk. Due to this backup node checkpoint process is more efficient than checkpoint node.
Backup node memory requirement is same as Namenode as it needs to maintain namespace in memory like Namenode. You can have only one backup node (multiple backup node are not supported at this point of time) and no checkpoint node can run, when backup node is running. Means you can have either backup node or checkpoint node, not both at a time.
Since backup node can maintain the copies of namespace in memory, you can start Namenode in a such a way that Namenode no longer needs to maintain namespace in its own memory, Namenode node can delegate this tack to backup node. In such case Namenode will import the namespace from backup node memory whenever it requires namespace. This can be done by starting Namenode with –importCheckpoint option.
No comments:
Post a Comment